1. 数据库的选择
假设数据名字为crashcourse,customers为其中的一张表。其中,最后两句话是相等的。
1 | USE crashcourse |
2. SELECT语句
- 选择所有的行、列可以用“*”。
- DISTINCT作用于所有的列。
- LIMIT a, b:从第a行开始的b行。
- 默认升序排列, 需要降序则在ORDER BY 之后添加 DESC。DESC只作用于直接位于其前面的列。
- where语句里面”!=”和”<>”表示不等于, 范围用BETWEEN和AND来操作。空值用 IS NULL。
- where语句可以使用操作符:AND, OR, IN, NOT。其中AND的优先级大于OR,NOT可以对IN、BETWEEN和EXISTS取反。
1 | SELECT DISTINCT C1, C2, C3 FROM customers WHERE C1 = 2.5 ORDER BY C1, C2 LIMIT 5 |
3.通配符
- “%”匹配任何字符出现任意次数(包括0个字符)。可以出现在任意位置’%jet’, ‘%jet%’和’j%j’。
- “_”匹配单个任意字符。
1 | SELECT DISTINCT C1, C2, C3 FROM customers WHERE C1 LIKE '%jet%' |
4.正则表达式
- OR搜索:REGEXP ‘1000|2000|3000’
- 匹配多个字符:REGEXP ‘[123] Ton’
- 匹配范围:[1-9], [1-6], [a-z]
- 转义:’\\-‘, ‘\\.‘
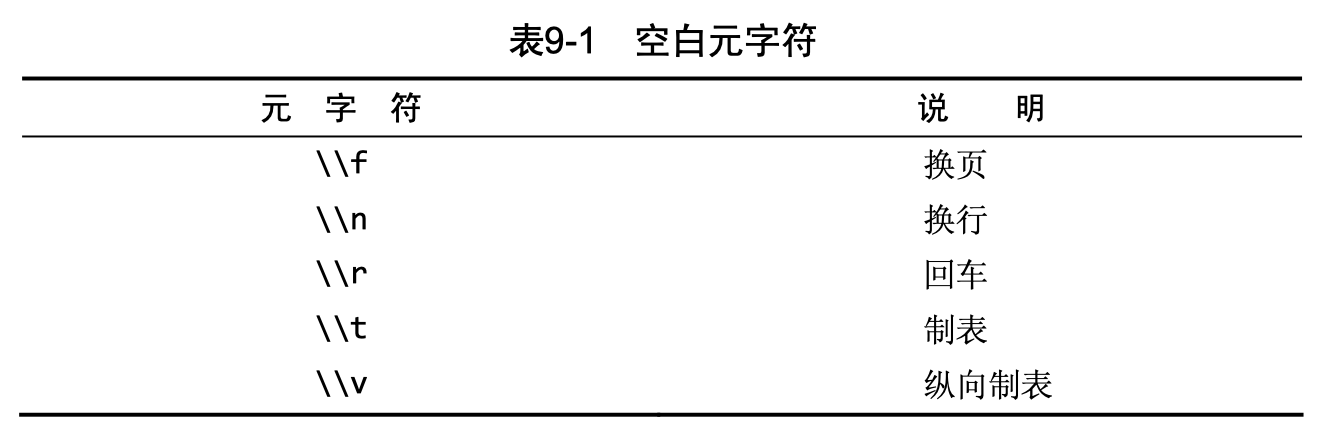


- 上表中,匹配元字符前面的的字符。n, m代表数字。
1 | SELECT C1 FROM customers WHERE C1 REGEXP '\\([0-9] sticks?\\)' ORDER BY C1 |
- 定位符:
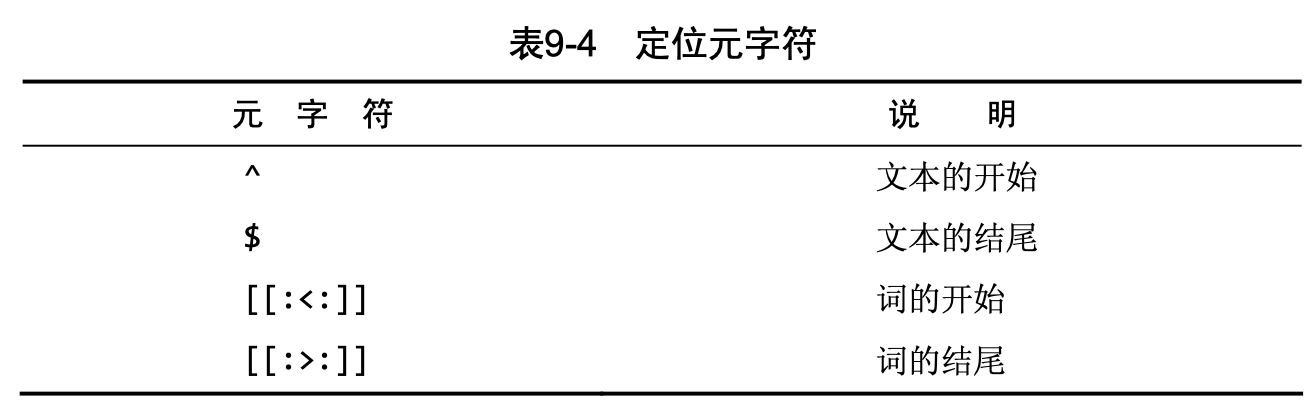
1 | SELECT C1 FROM customers WHERE C1 REGEXP '^[0-9\\.]' ORDER BY C1 |
5. 创建字段
- Concat用于拼接字段
1 | SELECT Concat(RTrim(C1), '(', RTrim(C2), ')') AS CCC FROM vendors ORDER BY C1 |
- 可执行算数,加减乘除
1 | SELECT C1, C2, C3, C2*C3 AS CCC FROM orderitem WHERE C1 = 2002 |
6. 函数
- 常用函数:


- 其中,Soundex是一个将任何文本串转化为描述其语音表示的字母数字模式的函数
1 | SELECT C1, C2 FROM vendors WHERE Soundex(C2) = Soundex('Lee') |
- 日期函数

- 关于日期的使用,需要注意格式,推荐使用’yyyy-mm-dd’。
- 同时,在筛选时间方面时,需要注意表中时间格式,例如是否带了小时,分钟之类的。
1 | SELECT C1, C2 FROM vendors WHERE Date(C2) = '2005-01-09' |
- 数值处理的函数

7. 汇总数据
- 聚集函数:运行在行组上,计算和返回单个值。
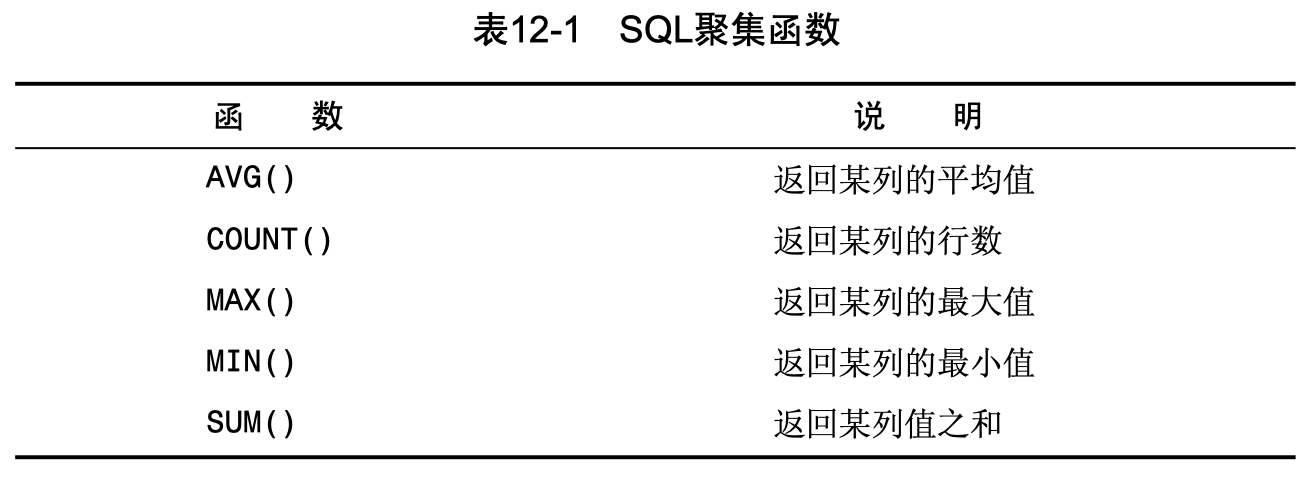
在函数里面可以添加DISTINCT
1 | SELECT AVG(DISTINCT C1) AS CCCC1, MIN(C1) AS DDDD1 FROM vendors |
8. 分组数据
- 使用GROUP BY,GROUP By指示MYSQL进行分组,然后对于每个组进行聚集。
- GROUP BY子句可以包含任意数据的列,因此可以对分组进行嵌套。数据将在最后规定的分组上进行汇总。
- 不能使用别名
- NULL会作为一个分组返回
- GROUP BY在WHERE之后,ORDER BY之前。
1 | SELECT C1, COUNT(*) AS CC2 FROM products GROUP BY C1 |
- 过滤分组使用HAVING,而不是WHERE。WHERE过滤指定的是行而不是分组。
1 | SELECT C1, COUNT(*) AS CCC2 FROM vendors WHERE C3 >= 10 GROUP BY C1 HAVING COUNT(*) >= 2 |
9. SELECT字句的顺序


10. 字句查询
- 语句嵌套
1 | SELECT C1, C2 FROM customers WHERE C2 IN (SELECT C2 FROM orderitems WHERE C3 = 'TTT') |
- 作为计算字段
1 | SELECT cust_name, cust_state, (SELECT COUNT(*) FROM orders WHERE orders.cust_id = customers.cust_id) AS orders FROM customers |
11. 联结
- 可联结多个表,用AND
1 | SELECT C1, C2, C3 FROM customers, products WHERE customers.C4 = products.C4 |
- 可以给表取别名
1 | SELECT C1, C2, C3 FROM customers AS a, products AS b WHERE a.C4 = b.C4 AND C1 = 'ttt' |
- 自联结
- 外部联结,指定包含所有行,LEFT或者RIGHT
1 | SELECT customers.cust_id, orders.order_num FROM customers LEFT OUTER JOIN orders ON customers.cust_id = orders.cust_id |
- 使用聚合函数
1 | SELECT customers.cust_name, customers.cust_id, COUNT(orders.order_num) AS num_ord FROM customers LEFT OUTER JOIN orders ON customers.cust_id = orders.cust_id GROUP BY customers.cust_id |
12. 组合查询
- 多条语句组合起来,使用UNION
- UNION中每个查询必须包含相同的列、表达式或聚合函数
- UNIOB自动去重,如果不想去重,使用UNION ALL
- 组合查询排序需要将ORDER BY放在最后一个SELECT语句之后,对所有行进行排序
1 | SELECT C1, C2 FROM products WHERE C1 > 5 |
13.全文本搜索
- 需要在创建表的时候添加FULLTEXT(C1)
- 使用函数Mathc()和Against()
- 全文本搜索的一个重要部分就是对结果的排序,优先返回较高等级的行
1 | SELECT C1 FROM productnotes WHERE Match(C1) Agaisnt('rabbit') |
- 排序等级由MySQL根据行中词的数目、唯一词的数目、整个索引中词的 总数以及包含该词的行的数目计算出来。
1 | SELECT C1, |
- 查询扩展,用于找到与搜索有关的行,即使不包含搜索的词
1 | SELECT C1 |
- 布尔文本搜索,用于全文本搜索,且可以:要匹配的词,要排斥的词,排列提示,表达式分组等
- 下面的例子搜索含有rabbit且排除包含 rope* (任何以 rope 开始的词, 包括 ropes)的行。
1 | SELECT C1 |


- MySQL规定了一条50%规则,如果一个词出现在50%以上 的行中,则将它作为一个非用词忽略。50%规则不用于IN BOOLEAN MODE。
- 如果表中的行数少于3行,则全文本搜索不返回结果(因为每个词 或者不出现,或者至少出现在50%的行中)。
- 忽略词中的单引号。例如,don’t索引为dont。
14.数据插入
- 插入的时候,每个列必须给值,如果没有值,则写NULL
1 | INSERT INTO customers |
- 上面这种表示不安全,因为依赖于表中列的顺序。下面这种更好但也更加繁琐。且使用这种方法可以省略列,但是省略列必须满足:该列定义为允许NULL值(无值或空值);在表定义中给出默认值。这表示如果不给出值,将使用默认值。
1 | INSERT INTO customers(C1, C2, C3) |
- 插入多行
1 | INSERT INTO customers(C1, C2, C3) |
- INSERT SELECT
1 | INSERT INTO customers(C1, C2, C3) |
- MySQL甚至不关心SELECT返回的列名。它使用的是列的位置,因此SELECT中的第一列(不管其列名)将用来填充表列中指定的第一个列,第二列将用来填充表列中指定的第二个列,如此等等。
- 可以添加WHERE来过滤数据
15. 更新数据
- UPDATE:更新特定行或者更新所有行
1 | UPDATE customers SET C1 = 'ssss', C2 = 'xxxx' WHERE C2 = 100055 |
- 如果将值设为NULL,就可以用来删除某个列的值。
16.删除数据
- DELETE:从表中删除特定的行或者所有的行。
- 不能忘记WHERE语句。
- DELETE用于删除行,如果要删除列需要用UPDATE
- 删除所有的行使用 TRUNCATE TABLE
1 | DELETE FROM customers WHERE C1 = 'sss' |
17.创建表
列名,数据类型,默认值
在创建新表时,指定的表名必须不存在。
如果你仅想在一个表不存在时创建它,应该在表名后给出IF NOT EXISTS。
表中的每个行必须具有唯一的主键值。且主键可以由多个列组成,但是要确保他们的组合是唯一的。
每个表只允许一个AUTO_INCREMENT列,而且它必须被索引(如通过使它成为主键)。
MySQL不允许使用函数作为默认值,它只支持常量。
引擎:
InnoDB是一个可靠的事务处理引擎,它不支持全文 本搜索;
MEMORY在功能等同于MyISAM,但由于数据存中,速度很快(特别适合于临时表);
- MyISAM是一个性能极高的引擎,它支持全文本搜索,但不支持事务处理。
1 | CREATE TABLE customers |
- 更新表,使用ALTER TABLE,ADD C1 CHAR(20)添加列,DROP CLOUMN C1删除列
1 | ALTER TABLE vendors ADD C1 CHAR(20) |
- 定义外键
1 | ALTER TABLE orderitems ADD CONSTRAINT fk_orderitems_products FOREIGN KEY (prod_id) REFERENCES customers (prod_id) |
- 重命名
1 | RENAME TABLE T1 TO T11, T2 TO T22 |
18.视图
- 视图不包含表中任何列或数据,它包含的是一个SQL查询。
视图规则
- 与表一样,视图必须唯一命名(不能给视图取与别的视图或表相同的名字)。
- 对于可以创建的视图数目没有限制。
- 为了创建视图,必须具有足够的访问权限。这些限制通常由数据库管理人员授予。
- 视图可以嵌套,即可以利用从其他视图中检索数据的查询来构造一个视图。
- ORDER BY可以用在视图中,但如果从该视图检索数据SELECT中也含有ORDER BY,那么该视图中的ORDER BY将被覆盖。
- 视图不能索引,也不能有关联的触发器或默认值。
- 视图可以和表一起使用。例如,编写一条联结表和视图的SELECT语句。
语句:
- CREATE VIEW,创建语句。
- SHOW CREATE VIEW viewname 来查看创建的视图语句。
- DROP VIEW viewname 来删除视图。
- 先DROP后CREATE 或者 CREATE OR REPLACE VIEW 来更新视图
- 可以用视图来过滤数据
- 可以用视图简化多次重复筛选
1 | CREATE VIEW prodcutcustomers AS |
1 | SELECT cust_name, cust_contact |
- 视图可以更新(INSERT, UPDATE, DELETE),但是如果包含以下操作,就不可以更新:
- GROUP BY, HAVING
- 联结
- 子查询
- 并
- 聚集函数,Min(), Count(), Sum() 等
- DISTINCT
- 导出计算列
19.存储过程
- 创建
1 | CREATE PROCEDURE productpricing() |
- 调用
1 | CALL productpricing() |
- 删除
1 | DROP PROCEDURE prodcutpricing |
- 使用变量
1 | CREATE PROCEDURE productpricing( |
1 | CREATE PROCEDURE ordertotal( |
- 只能存储过程
1 | -- Name: ordertotal |
- 显示存储过程
1 | SHOW CREATE PROCEDURE ordertotal |